.webp)

Emmanuel Uchenna
A software engineer, technical writer, and digital health advocate passionate about building technology that empowers people. With over five years of experience, he specializes in crafting clean, scalable user interfaces with React, Next.js, and modern web tooling, while also translating complex technical ideas into clear, engaging content through articles, documentation, and whitepapers.
Article by Gigson Expert
This guide covers 20 essential questions often asked in machine learning engineer interviews, ranging from fundamental concepts to advanced algorithms and deep learning. This guide will enable you to prepare for your next machine learning engineer interview.
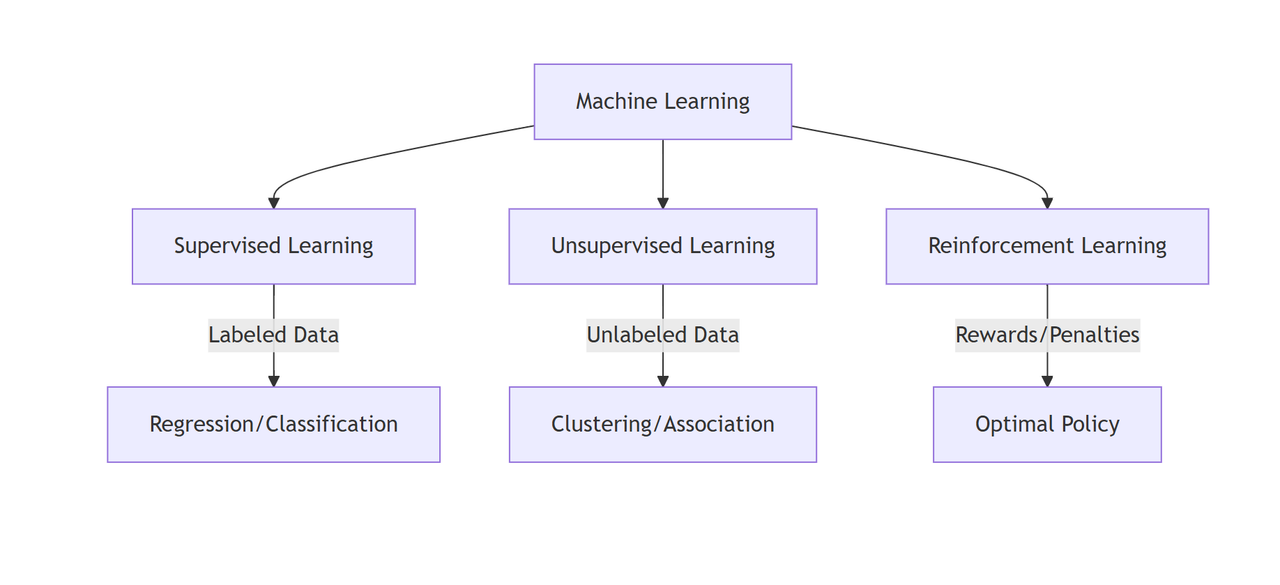
1. What are the main paradigms of Machine Learning?
Machine learning is generally categorized into three primary types based on how they learn from data:
- Supervised Learning: The model learns from a labeled dataset (training data includes input and correct output). It maps inputs to targets.
- Unsupervised Learning: The model learns from unlabeled data. It finds hidden structures, patterns, or clusters in the data without explicit guidance.
- Reinforcement Learning: An agent interacts with an environment and learns by receiving rewards or penalties for its actions, aiming to sustain positive feedback.
2. How does Supervised Learning differ from Unsupervised Learning?
The core difference lies in the data labeling:
- Supervised Learning: Requires input data to be paired with the correct output label. The goal is to train a model that can predict the output for new, unseen inputs.
- Usage: Fraud detection, email spam filtering, price prediction.
- Unsupervised Learning: Works with data that has no labels. The algorithm explores the data to find inherent structures.
- Usage: Customer segmentation, anomaly detection, topic modeling.
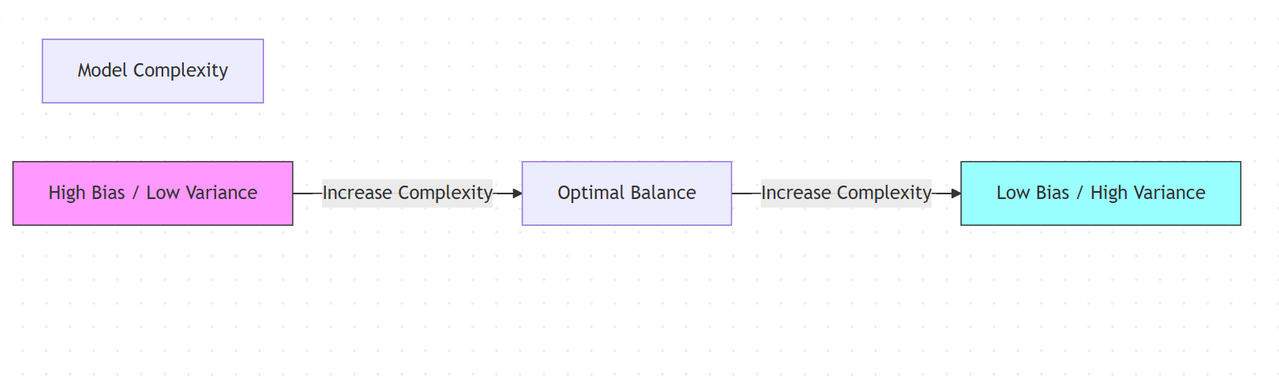
3. Explain the Bias-Variance Tradeoff
The Bias-Variance tradeoff is a central problem in supervised learning that involves finding the sweet spot between two sources of error:
- Bias: Error introduced by approximating a real-world problem with a simplified model. High bias can lead to underfitting (missing the relevant relations).
- Variance: Error introduced by the model's sensitivity to fluctuations in the training set. High variance can cause overfitting (modeling random noise).
Goal: Minimize Total Error = Bias² + Variance + Irreducible Error.
4. What is Overfitting, and how can it be prevented?
Overfitting happens when a model learns the training data too well, capturing noise and random fluctuations rather than the underlying pattern. This results in perfect training scores but poor performance on new (test) data.
Prevention Strategies:
- Regularization: Adding a penalty term to the loss function (e.g., L1/L2) to discourage complex models.
- Cross-Validation: Using techniques like K-Fold to ensure the model generalizes well.
- Pruning: Reducing the depth of decision trees.
- Simplifying the Model: Removing unnecessary features or parameters.
- Ensemble Methods: Using Random Forests or Bagging to average out variance.
5. Why do we need Training, Validation, and Test sets?
Data is split into three parts to ensure the model is built and evaluated correctly:
- Training Set (~60-70%): Used to fit the model parameters.
- Validation Set (~15-20%): Used to tune hyperparameters and select the best model version during development (prevents overfitting to the test set).
- Test Set (~15-20%): A completely unseen dataset used only once at the very end to provide an unbiased evaluation of the final model's performance.
6. How would you handle missing data in a time-series dataset vs. a general classification dataset?
The approach depends on the data type and patterns:
- General Classification (Independent rows):
- Imputation: Replace with Mean/Median (numerical) or Mode (categorical).
- Prediction: Use KNN or a regression model to predict missing values.
- Drop: Remove rows if missingness is <5%.
- Code:
df.fillna(df.mean()) or SimpleImputer(strategy='mean')
- Time-Series (Sequential rows):
- Constraint: You cannot use future data to predict past data (data leakage).
- Forward Fill: Propagate the last valid observation forward.
df.fillna(method='ffill') - Interpolation: Linear interpolation between points.
df.interpolate(method='linear')
7. What is a Confusion Matrix and why is it useful?
A Confusion Matrix is a table used to evaluate the performance of a classification model. It compares Actual values against Predicted values.

It allows the calculation of metrics such as Accuracy, Precision, Recall, and Specificity, which offer better insight than simple accuracy, especially for imbalanced datasets.
8. Differentiate between False Positives and False Negatives
- False Positive (Type I Error): You predict YES, but the truth is NO. (e.g., A spam filter incorrectly flags a legitimate email as spam).
- False Negative (Type II Error): You predict NO, but the truth is YES. (e.g., A medical test failing to detect a disease that is present).
Mnemonic:
- FP: False Alarm (You thought something happened, but it didn't).
- FN: Missed Detection (Something happened, but you missed it).
9. Define Precision and Recall
- Precision: Out of all predicted Positives, how many were actually Positive?
Precision = TP / (TP + FP)- Focus: Minimize False Positives (e.g., Spam Filter).
- Recall: Out of all actual Positives, how many did we catch?
Recall = TP / (TP + FN)- Focus: Minimize False Negatives (e.g., Cancer Detection)
from sklearn.metrics import precision_score, recall_score
# If you want to detect cancer (Recall is critical):
print(f"Recall: {recall_score(y_true, y_pred)}")10. When would you choose F1 Score over Accuracy?
Choose F1 Score when:
- Class Imbalance: You have highly uneven classes (e.g., 99% benign, 1% fraud). A model predicting "benign" for everything has 99% accuracy but 0 F1 score for the minority class.
- False Negatives/Positives Matter: You need a balance between Precision and Recall.
from sklearn.metrics import f1_score, accuracy_score
# In imbalanced sets, accuracy is misleading:
print(f"Accuracy: {accuracy_score(y_true, y_pred)}") # High (e.g. 0.99)
print(f"F1 Score: {f1_score(y_true, y_pred)}") # Low (e.g. 0.05)11. What is the difference between Type I and Type II Errors?
This is a statistical term for FP and FN:
- Type I Error: Null hypothesis is true, but you reject it (False Positive).
- Type II Error: Null hypothesis is false, but you accept it (False Negative).
12. What is Cross-Validation?
Cross-validation is a resampling technique used to assess how well a model generalizes to an independent dataset. K-Fold Cross-Validation is the most common:
- Partition the data into k equal subsets (folds).
- Train the model on k-1 folds.
- Test on the remaining 1 fold.
- Repeat k times, using a different fold as the test set each time.
- Average the results.
13. How does Deep Learning differ from traditional Machine Learning?
- Architecture vs Feature Engineering:
- Traditional ML (e.g., Logistic Regression, SVM) relies on manual feature engineering. You must define features like "pixel density" or "word count".
- Deep Learning (e.g., CNNs, Transformers) performs automatic feature extraction through multi-layered neural networks.
- Data & Hardware: DL thrives on massive datasets and requires GPUs (for matrix multiplication).
- Modern Context:
- Traditional:
scikit-learn,XGBoost (Tabular data). - Deep Learning:
PyTorch, TensorFlow, Keras(Unstructured data like Images/Text).
- Traditional:
14. What is Semi-Supervised Learning?
Semi-supervised learning sits between Supervised and Unsupervised. It uses a small amount of labeled data and a large amount of unlabeled data.
- Process: Use the small labeled set to train a basic model, use that model to pseudo-label the unlabeled data, and then retrain on the larger dataset.
- Benefit: drastically reduces the cost of manual data labeling.
15. Compare Inductive and Deductive Learning
- Inductive Learning (Bottom-Up): Observing specific instances to form a general rule. (e.g., "The sun rose today and yesterday, therefore it rises every day"). Most ML is inductive.
- Deductive Learning (Top-Down): Starting with general rules and applying them to specific instances. (e.g., "All birds have feathers. This is a bird, so it has feathers.”)
16. Why is Naive Bayes called "Naive"?
It is called "Naive" because it makes the assumption of conditional independence: it assumes that the presence of a particular feature in a class is completely unrelated to the presence of any other feature.
from sklearn.naive_bayes import GaussianNB
model = GaussianNB() # Assumes features are independent- Example: It considers a fruit an apple if it is red, round, and about 3 inches in diameter, independently of whether these features correlate with each other. Even though this assumption is often false in reality, the algorithm performs surprisingly well.
17. Explain how the K-Nearest Neighbors (KNN) algorithm works
KNN is a lazy learner algorithm used for classification and regression.
- Store all training data points.
- When a new point arrives, calculate its distance (usually Euclidean) to all other points.
- Select the K nearest data points.
- Vote: Assign the class that is most common among those K neighbors.
18. What is the difference between K-Means and KNN?
- K-Means: An Unsupervised algorithm used for Clustering. It groups data into K clusters based on centroids.
- KNN: A Supervised algorithm used for Classification. It classifies a point based on the labels of its neighbors.
19. What assumptions must be met for Linear Regression?
- Linearity: The relationship between X and Y is linear.
- Homoscedasticity: The variance of residual terms is constant at every level of X.
- Normality: The error terms are normally distributed.
- No Multicollinearity: Independent variables should not be highly correlated with each other.
- No Auto-correlation: Error terms should be independent.
20. What is the difference between Lasso (L1) and Ridge (L2) regularization?
Both methods prevent overfitting by adding a penalty term to the loss function.
- Lasso (L1): Adds penalty proportional to the absolute value of coefficients.
- $$ Cost = MSE + \lambda \sum |w_i| $$
- Effect: Can shrink coefficients to exactly zero (Feature Selection).
- Ridge (L2): Adds penalty proportional to the square of coefficients.
- $$ Cost = MSE + \lambda \sum w_i^2 $$
- Effect: Shrinks coefficients uniformly but rarely to zero.
from sklearn.linear_model import Lasso, Ridge
lasso = Lasso(alpha=0.1) # L1
ridge = Ridge(alpha=0.1) # L2
Frequently Asked Questions
How many rounds of coding are standard for ML roles?
Typically 3-5 rounds:
- Phone Screen: Basic Python/SQL or pure conversation.
- Coding (DSA): 1-2 rounds. Frequently LeetCode Medium (Arrays, Dictionary, Graphs).
- ML Theory/Design: 1 round. "Design a recommendation system" or "How does XGBoost work?".
- Behavioral: 1 round.
Do I need to know LeetCode style algorithms or just ML theory?
Yes, you need both. Most top-tier companies (FAANG) filter candidates with standard algorithmic coding rounds (Trees, Graphs, DP) before asking any ML questions. Do not neglect standard DSA.
Is Python the only language asked?
For ML roles, Python is the industry standard (95%+ of interviews). You might see SQL for data manipulation rounds. C++ is sometimes required for deployment/infrastructure roles (e.g., self-driving cars, high-frequency trading), but Python is usually sufficient for general ML/Data Science roles.
Wrapping Up
This article covered the most common Machine Learning interview questions and answers. It is a great resource for preparing for a Machine Learning Engineer interview.

.webp)