Efe Omoregie
Efe Omoregie is an Associate Staff Engineer at Yellow Card. With nearly a decade of software engineering experience, he has worked on payment systems, healthcare platforms, and cloud infrastructure. He is deeply passionate about computer science, programming and cloud computing.
Article by Gigson Expert
Building a SaaS product is one thing. Scaling it to thousands of tenants without accumulating technical debt, downtime surprises, or runaway cloud costs is another challenge entirely. In this article, we explore real-world architectural patterns used by SaaS companies, break down the trade-offs at each layer, and examine the practices that can separate products that grow from those that buckle under their own success.
The Multi-Tenant Foundation
Every SaaS system must answer a very important question early: how should tenant data be isolated? There are 3 widely used models, each with different cost and complexity curves.

Choosing the right database model is only one part of the isolation. At the API layer, tenant boundaries must be enforced on every request. The standard pattern is JWT-based tenant isolation: the identity provider embeds a tenant_id claim inside the signed token, and a middleware guard validates it before any handler runs.
Choosing the Right Starting Point: Microservices vs. Modular Monolith
A common mistake early-stage SaaS teams make is prematurely decomposing into microservices. The operational overhead of distributed tracing, inter-service auth, and separate deploy pipelines can easily overwhelm a small team before product-market fit is achieved.
The Modular Monolith Approach
Basecamp (now 37signals) runs its products as a Rails monolith. The key is strict internal module boundaries: each domain (billing, users, projects) lives in its own folder with no cross-module database joins. The key to a healthy monolith is strict internal module boundaries: each domain (billing, users, projects) lives in its own folder with a well-defined API. When a service genuinely needs to scale independently, extract it then.
When to Extract Microservices
Microservices make sense when a specific subsystem has materially different scaling requirements, release cadence, or team ownership. A well-known example comes from Netflix. Netflix began breaking apart its monolithic application as its streaming platform scaled rapidly. Different subsystems, such as user recommendations, video encoding, playback services, and billing, had very different operational characteristics. Some examples of when to extract to microservices
- Extract when a module requires a different language or runtime, e.g., ML inference in Python alongside a Typescript API layer.
- Extract when the blast radius must be minimised, e.g., a billing service bug should never take down the main dashboard.
- Extract when team boundaries and code boundaries need to align (Conway's Law in practice).
A useful heuristic is the two-pizza team rule applied to services: if a single team can own, deploy, and be on-call for a service end-to-end without needing coordination from another team, it is a reasonable extraction candidate. Services that require constant cross-team negotiation to change are a signal that the boundary was drawn in the wrong place.
Horizontal Scaling and the Stateless Service Contract
The prerequisite for horizontal scaling is stateless services. Each application instance must be able to handle any request without relying on local in-memory state. This means session data lives in Redis, uploaded files go to object storage (S3 / GCS), and long-running jobs are delegated to a queue.
Real-World Pattern: Notion's Scaling Journey
Notion migrated from a single PostgreSQL instance to a sharded setup after the single database began reaching scaling and operational limits. The key architectural decision was to shard by workspace ID, ensuring all data for a single tenant always lives on one shard (avoiding cross-shard joins) while distributing load across many database nodes. The initial sharding resulted in 480 logical shards across 32 physical databases. As Notion continued to grow, the team later re-sharded to 96 physical instances, maintaining 480 logical shards, using a zero-downtime migration with PgBouncer shard splitting.
Notion's own retrospective stresses that they should have sharded earlier. Waiting until their existing database was heavily strained added complexity. Always design sharding keys around the dominant access pattern, not the easiest join.
Event-Driven Architecture for Loose Coupling
As a SaaS product grows, synchronous request-response between internal services becomes a bottleneck and a reliability risk. Event-driven patterns using message brokers like Kafka, RabbitMQ, or AWS SQS decouple producers from consumers and enable durable, retryable workflows.
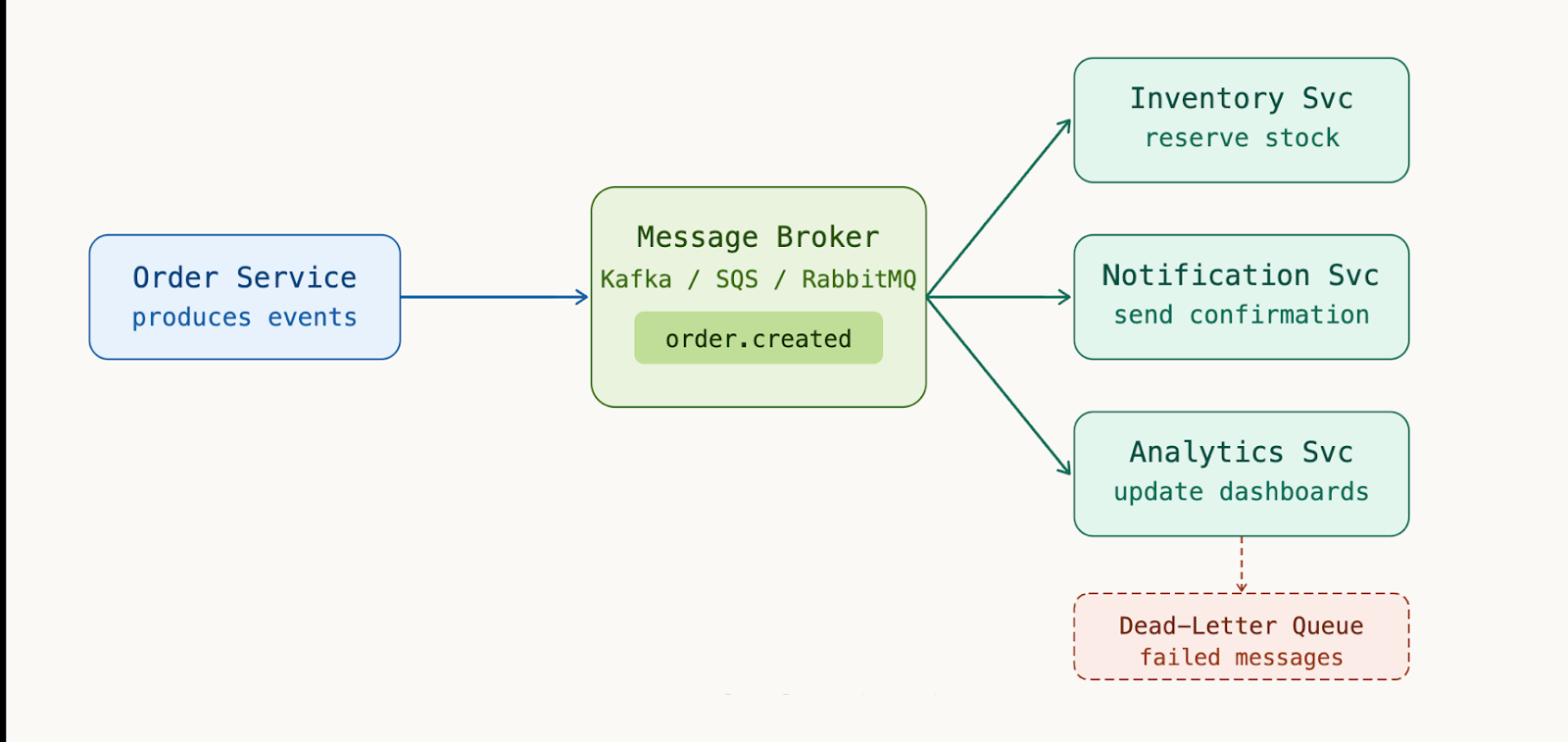
Some best practices to keep in mind:
- Use dead-letter queues (DLQ) for every consumer to prevent silent message loss.
- Version your event schemas using a schema registry.
- Keep events immutable and append-only.
Idempotency is another non-negotiable property for every event consumer. Message brokers guarantee at-least-once delivery, meaning any consumer may receive the same event more than once. Each consumer must be designed so that processing the same message twice produces the same result as processing it once.
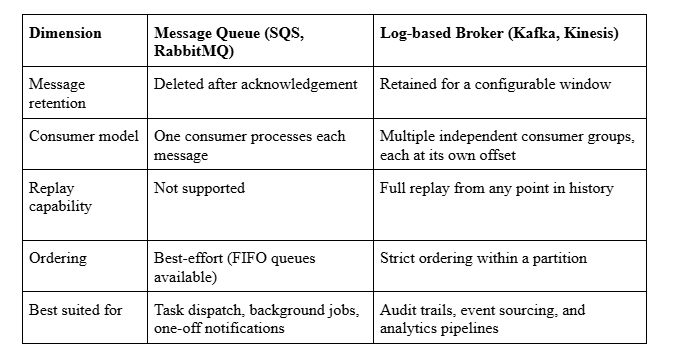
Choosing Your Broker: Queue vs. Log
The choice between a message queue and a log-based broker shapes your architecture. Here is a direct comparison to make that decision easier:
The Operational Backbone: Observability
At scale, you cannot debug what you can’t see. The three pillars of observability: logs, metrics, and traces must be built in from the start, not added after incidents. Any observability stack must include at least the following:
- Structured JSON logs sent to a centralised store (Datadog, Loki, or CloudWatch Logs Insights)
- Service-level metrics exported via Prometheus, displayed in Grafana dashboards with SLO burn-rate alerts
- Distributed traces captured with OpenTelemetry, which are essential for diagnosing latency across microservices
- Synthetic monitors that replay critical user flows (signup, checkout, login) every minute from multiple regions.
Service Level Objectives (SLOs) connect raw system metrics to user-facing reliability. Instead of alerting on every CPU spike or memory pressure event, SLOs define what good enough looks like from the user’s perspective. For example, an API might set an objective that 99.5% of requests complete within 300 ms over a rolling 30-day window. This framing shifts monitoring away from infrastructure noise and toward measurable service quality.
Error budgets make these objectives actionable. If a service is allowed 0.5% of requests to fall outside the SLO, that percentage becomes the team’s reliability budget for the period. Burn-rate alerts then trigger only when that budget is being consumed too quickly, indicating a real risk of violating the objective.
This approach dramatically reduces alert fatigue. Instead of reacting to every transient spike or isolated failure, teams receive signals only when reliability is meaningfully degrading. The result is a healthy operational loop: metrics feed into SLOs, SLOs define error budgets, and alerts fire only when those budgets are threatened. Monitoring stops being about watching dashboards and becomes about protecting the experience users actually depend on.
Closing Thoughts
SaaS architecture is never a one-time decision. Start with the simplest architecture that can ship and build module boundaries even inside a monolith. When scaling pressure arrives, you will have a solid foundation to make changes rather than emergency rewrites.
Frequently Asked Questions
Q: Is a monolith always the right starting point for a new SaaS product?
For most teams, yes, but the monolith must be modular from the start. The failure mode is not the monolith itself but the unstructured "big ball of mud" where every module reaches directly into every other module's database tables. Define boundaries, enforce them with linting or package visibility rules, and document which domain owns which tables.
Q: When does event-driven architecture introduce more problems than it solves?
Event-driven patterns can add operational overhead. For naturally synchronous workflows, a user submits a form and expects an immediate response, so forcing them through a queue will add latency and complexity for no benefit. Reserve event-driven design for fan-out scenarios, background jobs, and integrations where you want loose coupling. You should aim to keep your user-facing request paths synchronous and fast.
Q: What is the minimum observability stack a small SaaS team should have on day one?
Three non-negotiables:
- Structured JSON logs with a correlation/request ID on every log line.
- An uptime monitor (Better Uptime, Checkly, or even a free tier of Datadog Synthetics) that pages you the moment your signup or login flow breaks.
- Error tracking (Sentry free tier covers most early-stage needs) so exceptions surface immediately rather than via a user email.